Why Your AI Costs Keep Rising Even When Token Prices Fall

Gartner's forecast that LLM inference costs will fall 90% by 2030 is credible, but it describes token prices, not inference costs, and for enterprises deploying AI at production scale, that distinction is where most of the budget problem lives.
Token prices and inference costs are related but meaningfully distinct. Token prices are what model providers charge per unit of input and output. Inference costs are what enterprises actually spend to generate useful outputs from AI systems running in production — and that figure is shaped by far more than the per-token rate on a pricing page.
Agentic workloads consume 5 to 30 times more tokens per task than a standard prompt-response interaction, because each reasoning step, tool call, validation pass, and retry burns tokens independently. Orchestration overhead adds latency that compounds across pipeline steps, failed branches trigger reprocessing, and context windows grow as agent state accumulates across a session. A single edge case in a high-volume agentic workflow can cost 50 times what the nominal path does. And edge cases, by definition, are not what get optimised in a benchmark environment.
The result is a disconnect that Gartner’s own analysis flags explicitly: even as token unit costs fall, total inference spend for enterprises deploying agentic systems is expected to rise, because lower prices per token do not offset a 5 to 30 times increase in tokens consumed per task.
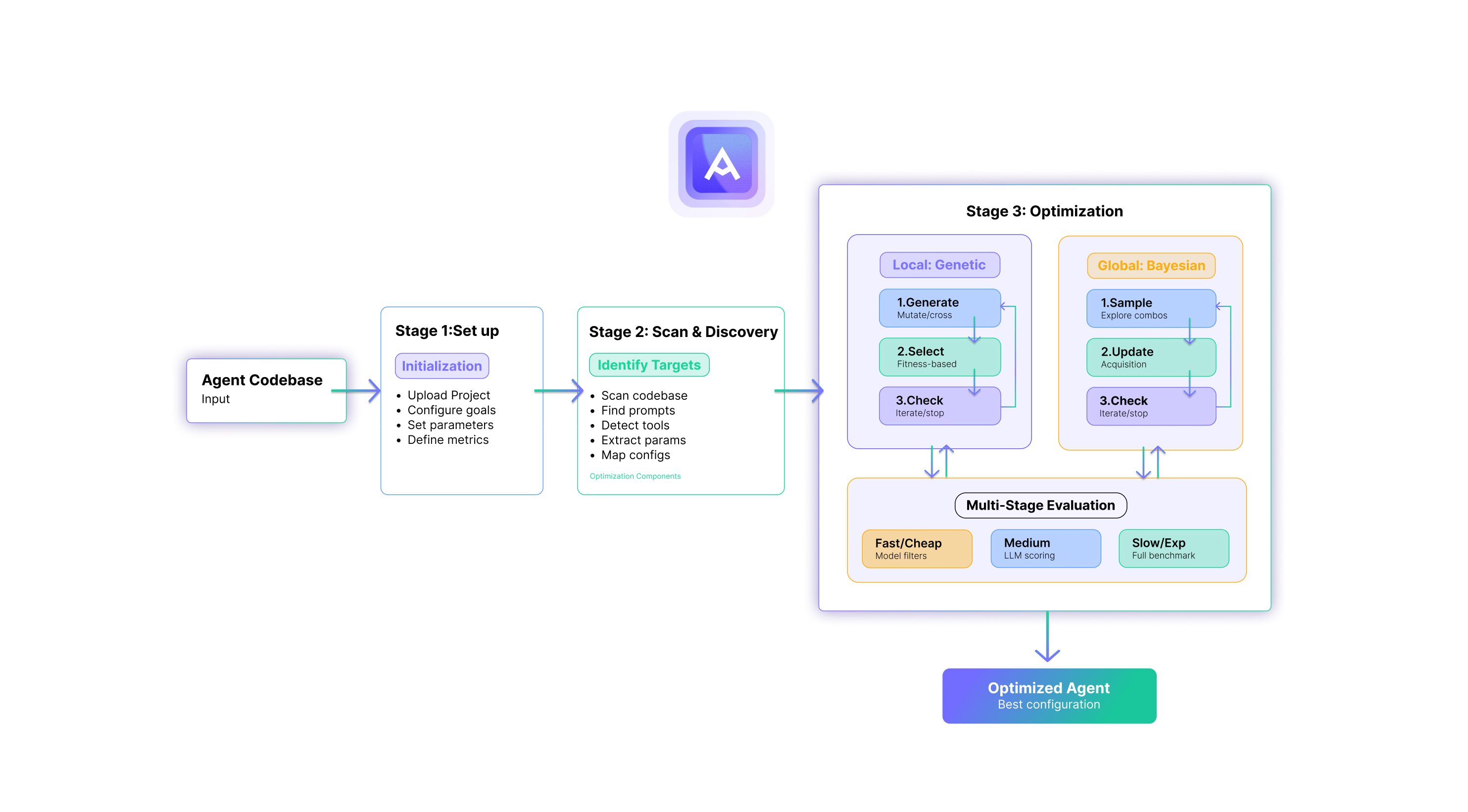
The Missing Layer
Most enterprises approaching production AI deployment have invested heavily in two areas: the models themselves, and the hardware infrastructure to run them. What they are typically missing is the layer in between — the capability that determines how efficiently models run on that hardware, how reliably pipelines execute at scale, and how systematically teams can improve performance across cost, latency, throughput, and output quality simultaneously.
This is not simply a model problem or a hardware problem. It is, at its core, both a data science and an engineering problem, and that combination is precisely why most teams struggle to solve it.
AI systems are probabilistic and non-deterministic. The same configuration that performed last quarter behaves differently as models update, usage scales, and workload distributions shift. Improving a system with these properties requires data science rigour: experiment design, multi-objective trade-off management, and statistical validation of results across repeated runs to distinguish real signal from noise. But it also requires engineering excellence: implementing changes safely in production code, validating outcomes against real workloads and real hardware, and ensuring that improving one metric doesn’t silently degrade another.
Most enterprises have one of these capabilities. Almost none have both working together on this problem systematically. The teams that do are treating inference optimisation as a practice — something that runs continuously as the environment evolves — rather than a project that gets revisited when something breaks.
The same principle applies at the agentic layer. Reliability in multi-step agent pipelines degrades predictably as pipeline depth increases, with an agent achieving 95% per-step accuracy producing roughly 60% end-to-end reliability across a 10-step workflow. Closing that gap requires optimising across competing objectives — reliability, latency, cost, and output quality — simultaneously rather than sequentially. Manual iteration across interdependent configuration spaces of this complexity does not reliably find the best outcome. It finds a local optimum that holds until traffic scales or the workload distribution shifts.
What This Means for 2026 Infrastructure Decisions
Enterprises that treat falling token prices as a reason to defer optimisation investment are making a structural error. The costs that matter most at agentic scale — orchestration overhead, retry rates, utilisation gaps, and multi-objective performance trade-offs — are not reduced by cheaper tokens. They are reduced by building the optimisation layer that most production AI stacks currently lack: the combination of data science and engineering discipline applied continuously to the gap between what infrastructure is capable of and what it actually delivers.
The infrastructure investment is already made. The models are already deployed. The agents are already being built. The question is whether the optimisation layer gets built before the cost structure becomes undefendable...or after. Most enterprises are finding out the hard way that after is considerably more expensive.