How Evolutionary Optimization Outperforms Manual Tuning for LLM-based Agents
AI agents are being used everywhere, from software engineering to scientific research. But there’s a problem: even well-designed agents often perform poorly and expensively because their configurations aren’t optimized. Bad prompts, unclear tool descriptions, and poorly chosen parameters don’t just hurt performance; they drive unnecessary token usage, tool calls, and retries that quietly inflate cost at scale. Manual optimization takes weeks of trial and error.
This challenge motivated us to explore automated agent optimization through evolutionary algorithms. To test this approach, we leveraged Artemis, TurinTech's general-purpose evolutionary optimization platform. Artemis is an AI-powered code intelligence platform that has evolved from earlier research on genetic algorithms for code generation into a production system capable of optimizing complex AI workflows. We applied its capabilities to the specific challenge of optimizing LLM-based agent configurations.
The Configuration Challenge
Modern LLM agents are not monolithic systems but multi-component pipelines. A typical agent coordinates system prompts, tool documentation, few-shot examples, and retry strategies, all of which interact in subtle ways. The resulting configuration space is high-dimensional and heterogeneous, encompassing natural language, discrete design choices, and continuous parameters.
In practice, manual tuning in such settings requires extensive trial-and-error and often still produces configurations that do not reliably generalize across tasks or deployment environments. We've observed that systematic optimization can improve agent performance by 9.3–13.6%, yet many practitioners rely on manual approaches that are both time-consuming and brittle.
Cost amplification: Poorly optimized agents don’t just perform worse. They are materially more expensive to run. Inefficient prompts, redundant tool calls, and unbounded retries inflate token usage, API spend, and wall-clock time. At scale, these inefficiencies compound: small configuration flaws can multiply cost across thousands or millions of agent executions, turning nominally functional agents into systems with unexpectedly high operating cost. In practice, teams often discover cost problems only after deployment, when usage patterns lock in inefficient behavior and optimization becomes harder to retrofit.
This isn't just curiosity. It creates real-world barriers:
- Time-consuming: weeks of manual refinement per agent
- Non-reproducible: different engineers produce different configurations
- Non-scalable: expertise doesn't readily transfer across domains or team members
- Brittle: even slight wording changes can cause dramatic performance shifts
- Missing interdependencies: optimizing components in isolation misses critical interactions
Existing optimization methods provide only partial relief. Prompt optimization techniques operate in isolation, while tool-focused approaches overlook critical interactions between components. Current methods typically ignore the wealth of information available in execution logs and benchmark feedback, leaving untapped opportunities for systematic improvement.
Our Approach: Leveraging Artemis for Agent Optimization
To overcome these challenges, we leveraged Artemis, TurinTech's general-purpose evolutionary optimization platform, to jointly optimize agent configurations through semantically aware genetic operators. Rather than restricting optimization to a single component, Artemis treats agents as black boxes, requiring no architectural modifications, and can jointly optimize multiple configurable components; both textual and parametric, while capturing their interdependencies.
Artemis builds on genetic algorithm research originally developed for code optimization, predating modern LLM-based systems. Rather than being limited to that domain, the underlying optimization techniques have been generalized into a production platform powered by TurinTech’s Intelligence Engine, capable of coordinating evolutionary search, machine learning models, and multi-agent workflows.
The same foundations are being extended beyond configuration optimization to support higher-level agent workflows, such as task decomposition, sequencing, and assignment within planning systems. In this study, we apply this platform specifically to the optimization of LLM-based agent configurations.
The system leverages benchmark outcomes and execution logs as feedback, applying semantically aware mutation and crossover operators specifically tailored for natural language components. In practice, Artemis automates most stages of the tuning workflow and is usable with only limited coding effort, making it accessible to practitioners without specialized evolutionary optimization expertise.
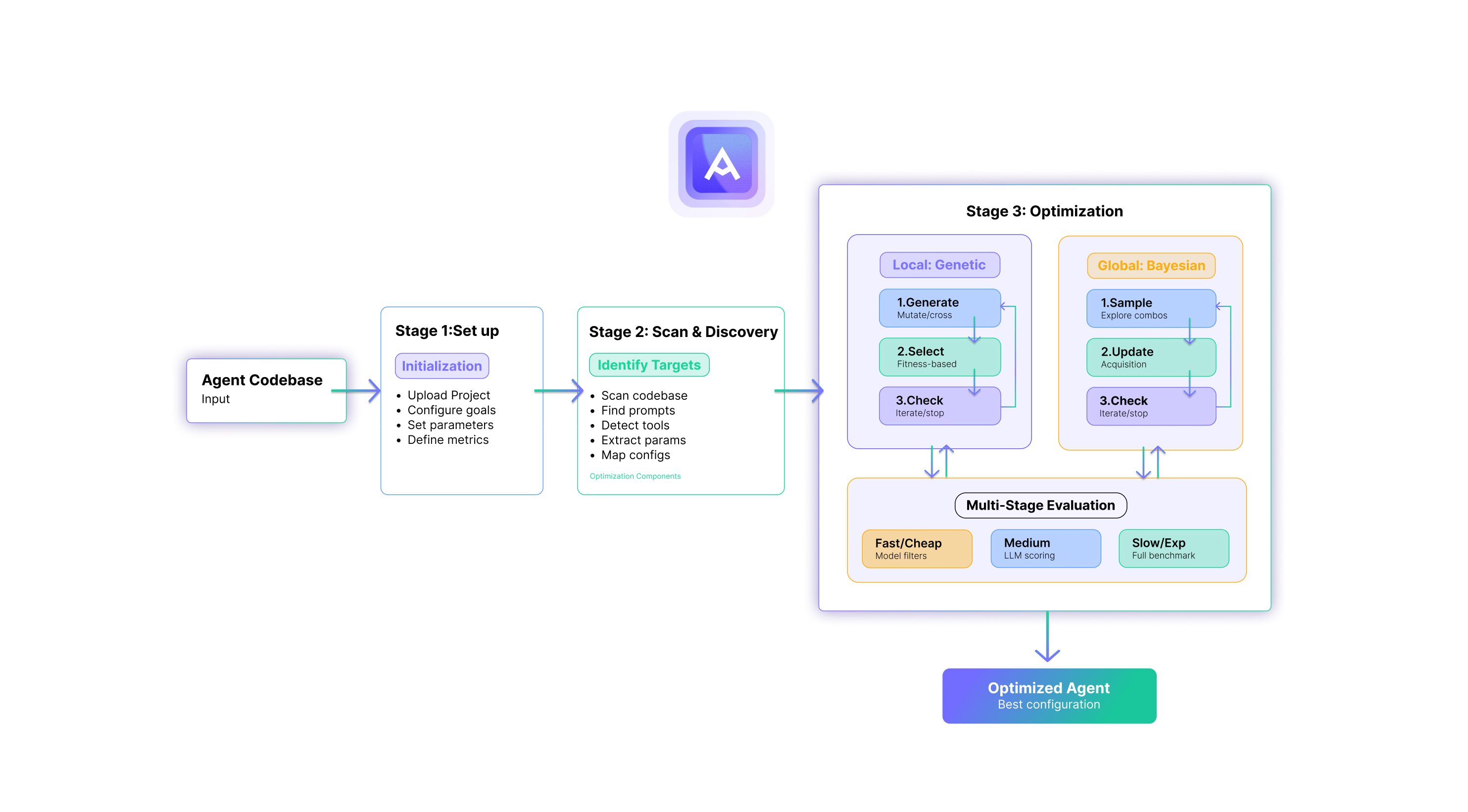
How Artemis Works
Artemis operates through three key stages:
1. Project Setup. Users upload their codebase, define optimization objectives in natural language (e.g., "maximize accuracy while reducing API calls"), specify the evaluation benchmark, and configure search parameters including choosing the LLMs to invoke.
2. Component Discovery. Artemis automatically analyzes the codebase structure to identify optimizable components such as prompts, tool descriptions, model parameters, and execution settings. The platform supports both global criteria (e.g., "find all prompts") and natural language queries (e.g., "find components related to error handling"), using semantic search to locate relevant code without manual specification.
3. Optimization Strategies. Once components and objectives are established, Artemis provides two complementary optimization approaches:
- Local Optimization: Evolves individual components independently using genetic algorithms. Each component undergoes semantic mutations and crossovers while maintaining contextual validity. Most suitable for components without strong interdependencies.
- Global Optimization: Uses Bayesian optimization to find optimal combinations when components interact. Explores the combinatorial space of component versions to identify synergistic configurations. Essential when prompt-tool interactions affect performance.
The optimization engine employs semantic genetic algorithms where LLM ensembles perform intelligent mutations that preserve meaning while exploring variations. Unlike traditional GAs operating on bit strings, Artemis maintains semantic validity throughout evolution. The hierarchical evaluation strategy balances efficiency with accuracy: cheap evaluators (LLM-based scoring, static analysis) filter candidates quickly, while expensive evaluators (full benchmark runs) validate only promising configurations.
Key advantages include: no coding required (natural language interface), automatic component discovery (semantic search eliminates manual specification), intelligent evolution (LLM-powered operators maintain validity), and black-box optimization (works with any agent architecture without modifications).
Results from Real-World Agent Systems
We evaluated Artemis across four distinct applications spanning different challenges: algorithmic reasoning, performance optimization, and mathematical discourse.
ALE Agent: Competitive Programming
The ALE Agent tackles competitive programming problems from AtCoder's Heuristic Contest, requiring sophisticated algorithmic reasoning and solution generation. We evaluated two optimization strategies: prompt optimization and search optimization using genetic algorithms.
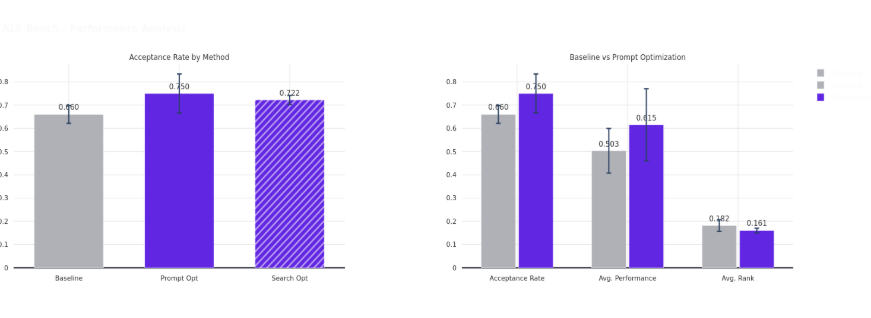
The ALE Agent achieved a 13.6% improvement in acceptance rate through prompt optimization, rising from 66.0% to 75.0%. The search-based optimization strategy yielded a 9.3% improvement, reaching 72.2%.
This transformation illustrates how Artemis evolves vague instructions into structured, effective prompts:

Key improvements focused on structured problem decomposition and explicit edge case handling. The optimized prompts guide the agent through systematic analysis phases rather than attempting immediate solution generation, resulting in more robust and correct implementations.
Mini-SWE Agent: Code Performance Optimization
Code performance optimization differs fundamentally from code testing or bug fixing, requiring a deep understanding of algorithmic complexity, data structures, and system bottlenecks while maintaining correctness. We evaluated on SWE-Perf, which tests agents on 140 optimization instances across nine major Python projects.
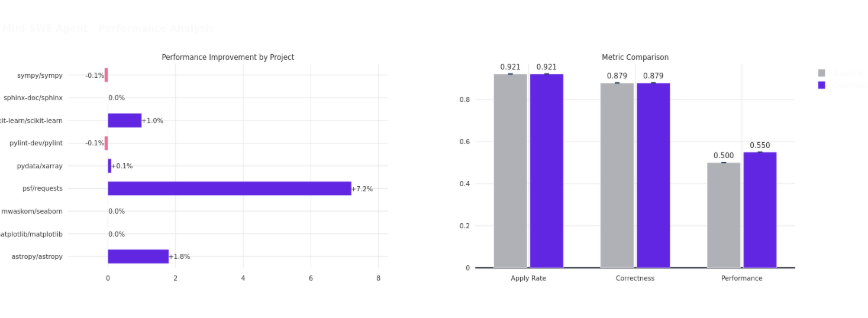
The Mini-SWE Agent demonstrated a statistically significant 10.1% performance improvement (p < 0.05), with apply rate and correctness maintained at 92.1% and 87.9%. Project-level results varied: requests showed +20% relative improvement (36.1%→43.3%), scikit-learn +29% (3.5%→4.5%), and astropy +62% (2.9%→4.7%).
The agent's behavior is controlled through YAML configuration files that specify optimization strategies. The optimization transformed a generic strategy into a targeted approach:
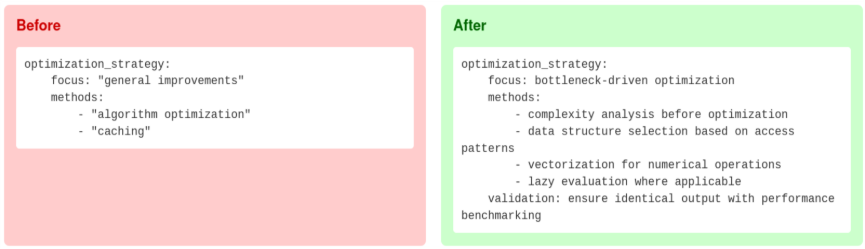
The improved configuration emphasizes targeting the single most critical performance bottleneck, systematic complexity analysis before optimization, and domain-specific techniques like vectorization and caching.
CrewAI Agent: Mathematical Reasoning
The CrewAI Agent handles conversational mathematical reasoning tasks through a streamlined two YAML file system without external tools. The agent processes natural language problem statements and generates step-by-step mathematical solutions.
The CrewAI Agent showed a significant 36.9% decrease in the average number of tokens used to evaluate the benchmark (p < 10⁻⁶). There was also a corresponding 36.2% decrease in the median cost per problem. The original configuration was already well-tuned for correctness, with little room for improvement, so we focused on optimizing for cost efficiency.
The agent uses YAML configuration files to define two roles: a researcher agent that solves problems and a reporting analyst that evaluates solutions. Here's how Artemis optimized the configuration:

Artemis modified each prompt and set reasonable token limits. The result is that problems with exceptional expense are intentionally failed early at zero cost. In contrast, medium-difficulty problems are executed more efficiently, as evidenced by the changes in average and median costs. This demonstrates Artemis's capability to optimize for cost efficiency when performance is already well-tuned.
MathTales-Teacher Agent: Primary-level Math Problem Solving
MathTales-Teacher agent is designed to solve primary-level mathematics questions and provide a foundation for generating mathematical stories. The agent is powered by Qwen2.5-7B, demonstrating that Artemis effectively optimizes agents based on smaller open-source models.
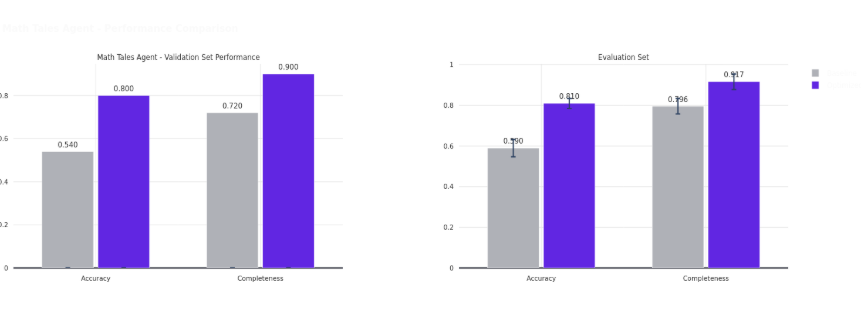
The optimized agent achieves an average completion rate that is 12.1% higher than the baseline and an average accuracy that is 22% higher.
The agent uses prompts to guide its solving action. Here's how Artemis optimized the prompt:

These findings demonstrate that the optimization performed by Artemis generalizes effectively to broader problem distributions within the GSM8K benchmark, validating that evolutionary optimization is not limited to commercial LLM-based agents and can enhance local LLM-based systems.
Aggregate Performance Analysis
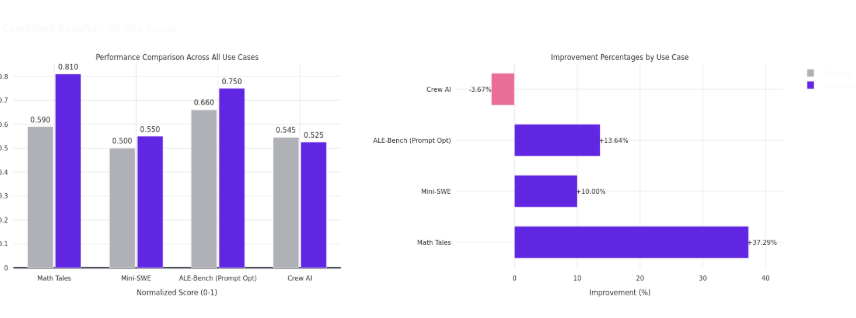
Our comprehensive evaluation across four diverse agent systems demonstrates Artemis's effectiveness in automated optimization, though with notable variations in success patterns and optimization objectives. Three out of four agents showed statistically significant improvements in their primary performance metrics, with improvements ranging from 9.3% to 36.9% for successful optimizations.
The ALE Agent achieved the largest absolute improvement in acceptance rate (+13.6% through prompt optimization). The Mini-SWE Agent showed statistically significant improvement (p < 0.005) with a 10.1% gain in performance score. The MathTales-Teacher Agent exhibited strong improvements in both accuracy (+22%, p < 0.001) and completion rate (+12.1%, p < 0.001). The CrewAI Agent achieved a dramatic 36.9% reduction in token cost (p < 10⁻⁶), demonstrating Artemis's capability to optimize for cost efficiency when performance is already well-tuned.
Key Insights and Practical Guidelines
Our evaluation reveals several critical insights about automated agent optimization:
Optimization Effectiveness Factors. Success depends on three key factors: (1) the quality of the initial configuration; poorly tuned agents show greater improvement potential; (2) the nature of the task; well-defined metrics like acceptance rate or performance score enable better optimization than subjective reasoning tasks; and (3) the optimization strategy; prompt optimization excels for instruction clarity while search strategies work for systematic exploration.
Computational Trade-offs. While optimization requires significant computational resources, the resulting improvements often justify the investment. The total optimization time varied significantly across agents: 671.7 hours for ALE Agent (due to expensive competitive programming evaluations), 9 hours for Mini-SWE, reflecting the computational cost differences between benchmark types. Importantly, configurations optimized for performance typically maintain similar runtime cost to baselines while delivering better performance.
When Optimization Works Best. Automated optimization is not universally beneficial. Practitioners should assess their agents' baseline quality and task characteristics before investing in optimization efforts. Agents with vague or generic prompts are better candidates than carefully tuned systems. Clear performance metrics are essential; subjective or multi-faceted success criteria complicate optimization. For reasoning-heavy tasks, prioritize prompt optimization over parameter search.
Importantly, performance gains are only part of the story. Several of the optimizations we observed translated directly into lower operational cost. By reducing unnecessary reasoning depth, eliminating redundant retries, and enforcing tighter execution bounds, optimized agents consumed fewer tokens and completed tasks faster. This matters in production settings where agent costs scale linearly with usage volume: even modest per-task savings can result in substantial budget reductions over time. In this sense, automated optimization is not just about making agents better—it is about making them economically viable.
Why Automated Optimization Matters
Enterprises don't adopt AI tools because of impressive demos; they adopt them when outcomes are consistent, validated, and trustworthy. Our research addresses one of the biggest barriers we've seen in practice: the unpredictability and brittleness of manual configuration tuning.
By applying general-purpose optimization platforms like Artemis to agent configuration, we demonstrate that systematic optimization can help practitioners improve agent performance without requiring deep expertise in evolutionary algorithms. Artemis's no-code interface democratizes sophisticated optimization, enabling teams to transform vague instructions into structured, effective prompts that uncover non-obvious optimizations.
As LLM agents become increasingly prevalent in production systems, automated optimization approaches will play a crucial role in bridging the gap between theoretical agent potential and practical deployed performance. Our results show that automated agent optimization through evolutionary methods is practical and effective, making sophisticated optimization accessible to practitioners without requiring deep expertise in evolutionary algorithms.

