Meta-Prompted Code Optimization: Making AI Outcomes More Reliable

At TurinTech, our work on Artemis is guided by a simple question: how do we make AI-powered engineering not just faster, but more reliable and consistent? Software performance is a useful proving ground. Even small runtime improvements can produce major real-world gains in cost, energy efficiency, and user experience.
Yet, as we built Artemis, we encountered a fundamental challenge: results from AI models were inconsistent. A prompt that produced strong improvements on one model often degraded performance on another. This brittleness made optimization hard to scale and difficult to trust — especially for enterprises that need predictable outcomes across different models, codebases, and workloads.
That challenge motivated our research into Meta-Prompted Code Optimization (MPCO), a new approach designed to improve the quality and reliability of AI-driven code optimization.
The Challenge of Cross-Model Consistency
In our production deployments, we saw a recurring issue: optimization results varied dramatically depending on which model was used and how prompts were written.
For example, when optimizing the same function from the Llama.cpp repository across different LLMs, we found:
- GPT-4o delivered its best result (116.1s runtime) with a GPT-specific prompt.
- Using Claude’s prompt template with GPT-4o worsened runtime by 23.5%.
- Using Gemini’s template degraded performance by 29.0%.

Similar inconsistencies held true when reversing the experiment: Claude and Gemini both performed worse when forced to use a prompt template designed for another model.
This isn’t just a curiosity. It creates real-world barriers:
- Maintenance overhead — every model-task combination requires its own hand-tuned prompts.
- Lock-in risk — teams get stuck on a single model because switching undermines results.
- Scalability limits — each new model multiplies prompt engineering complexity.
- Outcome instability — performance gains are unpredictable across environments.
For a platform like Artemis, which deliberately uses multiple models to broaden the optimization space, this inconsistency posed a fundamental bottleneck.
Our Contribution: Meta-Prompted Code Optimization (MPCO)
To overcome this, our team developed MPCO, a framework that automates the generation of model-specific prompts. Instead of relying on fixed templates, MPCO uses a meta-prompter — an AI system that understands the optimization challenge, the target codebase, and the characteristics of each model — to dynamically generate tailored instructions.
This turns prompt engineering from a brittle, manual process into an adaptive, scalable system.
How MPCO Works
MPCO operates through four stages:
1. Bottleneck Discovery
Profiling tools such as Intel VTune and Speedscope identify the code functions most responsible for performance issues. Optimizations target these high-impact areas rather than arbitrary code.
2. Context-Aware Prompting
The meta-prompter generates instructions by considering three layers of context:
• Project context (language, code structure, architecture).
• Task context (optimization goal, e.g. runtime, memory use).
• Model context (capabilities and characteristics of the LLM).
The result is a custom prompt tuned to the strengths of each model.
3. Multi-Model Optimization
Tailored prompts are run across several models in parallel, widening the solution space and reducing dependence on any one model.
4. Automated Validation
Candidate optimizations are compiled, tested against existing unit tests, and benchmarked for runtime improvements. Only validated results advance.
.jpg)
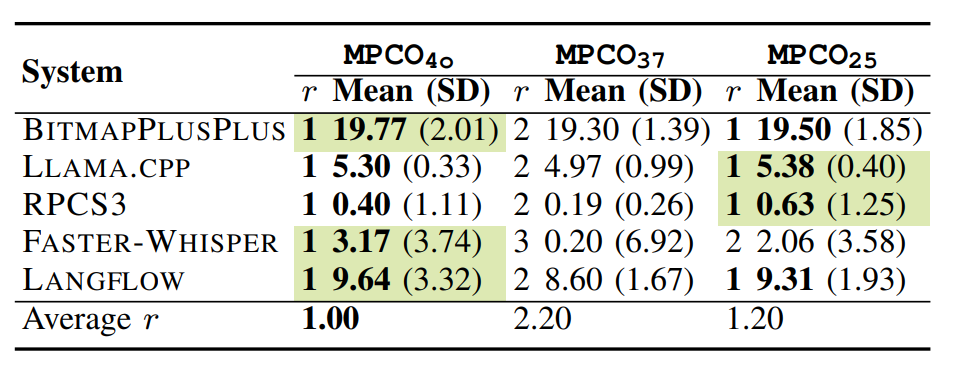
Results from Real-World Codebases
We evaluated MPCO across five enterprise-scale projects, subjecting each optimization to hundreds of hours of benchmarking and validation. Key findings include:
- Outcome consistency: optimizations held across multiple models, avoiding the degradation seen with fixed prompt templates.
- Performance gains: up to 19.06% improvement in runtime efficiency.
- Reliability: all optimizations passed automated correctness checks (compilation, unit tests).
While performance improvements are significant, the more important result is predictable outcomes. MPCO reduces brittleness and improves trustworthiness when scaling optimization across models.
Beyond performance gains, MPCO strengthens key components across the Artemis platform, elevating prompt quality and adaptability across the agentic engineering lifecycle to deliver more reliable outcomes.
Why Outcome Quality Matters
Enterprises don’t adopt AI tools because of impressive demos; they adopt them when outcomes are consistent, validated, and trustworthy. MPCO addresses one of the biggest barriers we’ve seen in practice: unpredictability.
By making optimization more robust across models, MPCO helps Artemis deliver on its larger promise — evolving code toward outcomes that matter, whether that means lower latency, reduced compute cost, better maintainability, or higher reliability.

